AI applications are only as good as the context they can retrieve — and most context is relational by nature. Entities reference other entities: a customer knows a vendor, a drug interacts with a protein, a code module depends on a library. Flattening these relationships into rows and columns works until it doesn't, and in knowledge-intensive AI workloads it usually stops working fast. Graph databases model the world the way it actually is: nodes, edges, and properties that mirror how humans and LLMs reason about connected information. This post walks through exactly how to build that infrastructure, from raw Cypher queries to production-grade GraphRAG pipelines.
- Knowledge graphs store entities and their relationships as first-class citizens — not as foreign keys buried in join tables.
- Neo4j's Cypher query language lets you traverse multi-hop relationships in a single readable statement that would require recursive CTEs in SQL.
- GraphRAG combines graph traversal with vector similarity search so your LLM retrieves both semantically similar chunks and structurally related entities.
- Graph databases win on relationship-heavy, variable-depth queries; relational databases still win on aggregation, ACID transactions, and columnar analytics.
- Production AI stacks increasingly combine Neo4j (or a compatible graph store) with a vector database rather than choosing one over the other.
What Is a Knowledge Graph
A knowledge graph is a directed, labeled multigraph in which nodes represent entities (people, places, concepts, documents) and edges represent typed relationships between them. Every node and edge can carry an arbitrary set of key-value properties. The result is a data structure that encodes not just facts but the semantic connections between facts.
The canonical academic definition comes from Google's 2012 announcement, but the underlying property graph model predates it significantly. What changed in the AI era is the use case: instead of powering search result cards, knowledge graphs now serve as the structured memory that LLMs query to ground their outputs in verifiable, traceable facts.
A minimal knowledge graph for a software engineering domain might look like this:
// Create nodes
CREATE (alice:Engineer {name: 'Alice', level: 'senior', team: 'platform'})
CREATE (bob:Engineer {name: 'Bob', level: 'mid', team: 'ml'})
CREATE (pg:Technology {name: 'PostgreSQL', type: 'relational'})
CREATE (neo:Technology {name: 'Neo4j', type: 'graph'})
// Create relationships
CREATE (alice)-[:KNOWS {since: 2021}]->(bob)
CREATE (alice)-[:EXPERTISE_IN]->(pg)
CREATE (bob)-[:EXPERTISE_IN]->(neo)
CREATE (alice)-[:EXPERTISE_IN]->(neo)The KNOWS edge itself carries metadata (since: 2021), something that in a relational model would require a separate junction table with its own foreign keys. That conciseness compounds as graph depth increases.
Label your relationship types as verbs in SCREAMING_SNAKE_CASE (EXPERTISE_IN, REPORTS_TO, CITES) and your node labels as nouns in PascalCase (Engineer, Document). Consistent naming conventions make Cypher queries self-documenting and reduce the friction of onboarding new team members into an unfamiliar graph schema.
Graph vs Relational for Relationship-Heavy Data
The performance gap between graph and relational databases becomes stark at query-time when you need variable-depth traversal. Consider the classic social-graph problem: find everyone within six hops of a given person. In PostgreSQL you would write a recursive CTE:
WITH RECURSIVE friends_of(person_id, depth) AS (
SELECT target_id, 1
FROM relationships
WHERE source_id = :start_id
UNION ALL
SELECT r.target_id, f.depth + 1
FROM relationships r
JOIN friends_of f ON r.source_id = f.person_id
WHERE f.depth < 6
)
SELECT DISTINCT person_id FROM friends_of;This query forces the planner to perform up to six self-joins on the relationships table. At moderate scale (millions of rows), the intermediate result sets explode in size and the query time grows super-linearly with hop depth. Index nested loop joins help at shallow depths but degrade rapidly.
In Neo4j the equivalent is a single, readable Cypher pattern:
MATCH (start:Person {name: 'Alice'})-[:KNOWS*1..6]->(reachable:Person)
RETURN DISTINCT reachable.nameNeo4j's native graph storage keeps adjacency lists directly on disk alongside node records. Traversal is pointer-chasing at the storage layer rather than join-planning at the query layer. The practical result is that six-hop traversals that take minutes in PostgreSQL execute in milliseconds in Neo4j against graphs with tens of millions of relationships.
| Workload | Relational (PostgreSQL) | Graph (Neo4j) |
|---|---|---|
| Multi-hop traversal (≥3 hops) | Recursive CTEs; degrades super-linearly | Native pointer-chasing; near-constant per hop |
| Aggregate analytics (SUM, GROUP BY) | Excellent — columnar indexes, parallel scans | Adequate but not optimized for bulk aggregation |
| ACID transactions | Mature, battle-tested | Supported in Neo4j Enterprise; lighter in embedded stores |
| Schema flexibility | Rigid; ALTER TABLE for every property change | Schema-optional; add properties without migration |
| Entity relationship density | Practical up to ~3–4 join tables | Designed for hundreds of relationship types |
| Tooling and ecosystem | Enormous — ORMs, BI tools, managed cloud options | Growing — Bloom, GDS plugin, AuraDB |
The takeaway is not that graph databases are universally superior — it is that each storage engine is optimized for a different query shape. The question to ask is: does my query look like a join or does it look like a traversal?
Neo4j Cypher: Basic Queries and Patterns
Cypher uses ASCII-art syntax to express graph patterns directly in the query. Parentheses are nodes, square brackets are relationships, and arrows indicate direction. Once you internalize that grammar, complex queries become remarkably readable.
The most fundamental pattern — finding immediate neighbors — is exactly what it looks like:
MATCH (p:Person)-[:KNOWS]->(friend)
WHERE p.name = 'Alice'
RETURN friendThis returns all Person nodes that Alice has an outgoing KNOWS relationship to. Extend it to return properties, filter by friend attributes, or traverse further hops:
// Return friends who are also engineers, with the relationship metadata
MATCH (p:Person)-[r:KNOWS]->(friend:Engineer)
WHERE p.name = 'Alice'
AND friend.level = 'senior'
RETURN friend.name, r.since
ORDER BY r.since DESC// Find the shortest path between two people
MATCH path = shortestPath(
(alice:Person {name: 'Alice'})-[:KNOWS*]-(target:Person {name: 'Carol'})
)
RETURN path, length(path) AS hops// Aggregate: count how many engineers each person knows
MATCH (p:Person)-[:KNOWS]->(e:Engineer)
RETURN p.name, count(e) AS engineer_connections
ORDER BY engineer_connections DESC
LIMIT 10Use EXPLAIN and PROFILE in the Neo4j Browser to inspect query plans before running them in production. The planner can sometimes scan all nodes of a label if it lacks a good starting anchor — always ensure your entry-point properties (name, id) have a uniqueness constraint and index backing them: CREATE CONSTRAINT FOR (p:Person) REQUIRE p.id IS UNIQUE.
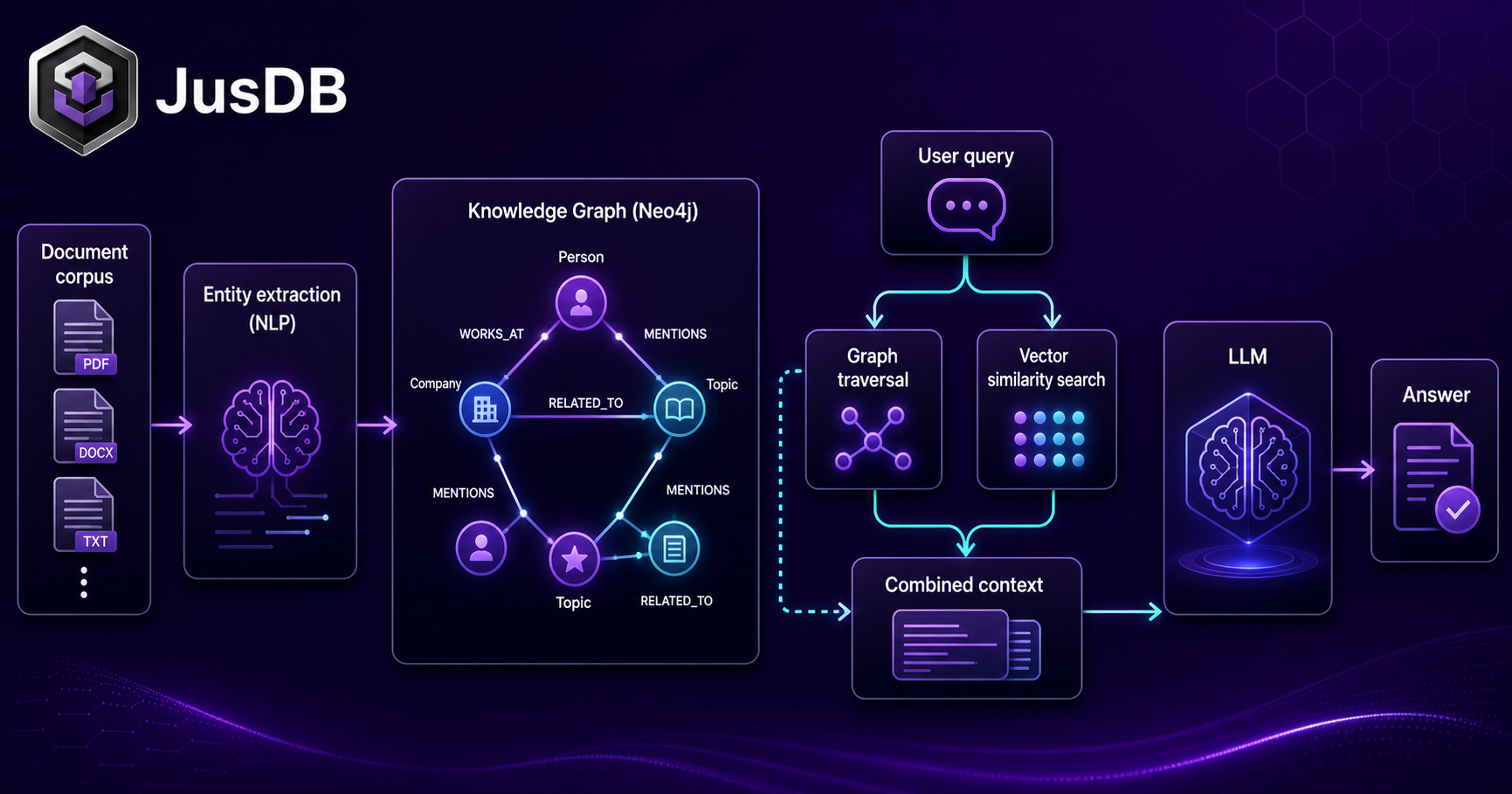
Graph-Enhanced RAG (GraphRAG)
Standard Retrieval-Augmented Generation retrieves the top-k chunks most similar to a user query by cosine distance in a vector space. This works well for semantic similarity but fails on structural or relational questions: "Which drugs interact with compounds that inhibit the same receptor as ibuprofen?" No vector similarity query can answer that directly — the answer lives in a traversal.
GraphRAG addresses this by maintaining two parallel data structures: a vector index for semantic retrieval and a knowledge graph for relationship traversal, then combining them at query time. The pattern has three stages:
1. Ingestion — entity extraction and relationship storage
At index time, run an extraction pipeline (typically an LLM prompt or a fine-tuned NER model) over your document corpus to identify entities and their relationships. Store both the graph structure in Neo4j and dense vector embeddings in your vector store (pgvector, Pinecone, Weaviate, etc.):
// Store extracted entities and their source document
MERGE (drug:Drug {name: $drug_name})
MERGE (doc:Document {id: $doc_id, title: $doc_title})
MERGE (protein:Protein {name: $protein_name})
MERGE (drug)-[:MENTIONED_IN]->(doc)
MERGE (drug)-[:INHIBITS {confidence: $confidence}]->(protein)
SET drug.embedding = $embedding_vector // store vector on node property
SET doc.ingested_at = datetime()2. Retrieval — hybrid graph + vector search
At query time, use vector similarity to find the most relevant seed entities, then expand outward through the graph to surface structurally related context that pure vector search would miss:
// Step 1: vector similarity to find seed entities (using Neo4j Vector Index)
CALL db.index.vector.queryNodes('drug-embeddings', 5, $query_embedding)
YIELD node AS seed, score
// Step 2: expand graph neighborhood of each seed
MATCH (seed)-[:INHIBITS|:ACTIVATES|:BINDS_TO*1..2]->(related)
RETURN seed.name, related.name, labels(related) AS type, score
ORDER BY score DESC3. Augmentation — inject structured context into LLM prompt
Format the retrieved subgraph as a structured context block in your system prompt. The LLM receives not just semantically similar text chunks but a precise, verifiable chain of relationships that anchors its response in your knowledge base. Hallucination rates drop measurably when the model can cite explicit graph paths rather than interpolating from fuzzy semantic neighborhoods.
Microsoft's published GraphRAG research (2024) demonstrated that this hybrid approach outperforms naive RAG on multi-hop reasoning tasks by 15–40% depending on the benchmark — the gains are largest precisely in the cases where relationship context matters most.
When to Use Graph vs Vector Databases
Neither graph nor vector databases are monolithic solutions. The right choice depends on query shape, update patterns, and the nature of the AI task you are supporting.
| Criterion | Use Graph (Neo4j) | Use Vector (pgvector, Pinecone) |
|---|---|---|
| Query type | Multi-hop relationship traversal, path-finding, subgraph matching | Semantic similarity, nearest-neighbor search, fuzzy matching |
| Data structure | Highly connected entities with typed, named relationships | Unstructured or semi-structured text, image, or code embeddings |
| AI use case | Reasoning over known entities; structured knowledge recall | Open-domain retrieval; "find similar documents" tasks |
| Update frequency | Moderate — graph mutations are transactional but not bulk-append-optimized | High — vector stores handle streaming upserts well |
| Explainability | High — every result comes with a traceable path | Lower — similarity score alone doesn't explain why |
| Cold start | Requires entity extraction pipeline to populate graph | Fast — embed and index in one pass |
The production-grade answer for most serious AI applications is: use both. A graph store handles the structured memory layer — who knows whom, what drug inhibits what, which module depends on which — while a vector store handles the unstructured retrieval layer. They complement rather than compete, and routing queries to the right retriever is itself a solvable engineering problem.
If you are already running PostgreSQL and want to experiment with graph-like queries before committing to Neo4j, the pg_graphql extension and Apache AGE (a PostgreSQL extension that implements the openCypher query language) let you run Cypher-style queries on a PostgreSQL backend. This is not a replacement for native graph storage at scale but it substantially lowers the barrier to evaluation.
Key Takeaways
- Knowledge graphs model entities and relationships as first-class citizens, making them the natural backing store for AI systems that need to reason over connected information.
- Neo4j's native graph storage traverses six-hop relationships in milliseconds where recursive SQL CTEs degrade super-linearly — the performance gap is architectural, not tuning-related.
- Cypher's ASCII-art syntax (
MATCH (p:Person)-[:KNOWS]->(friend) WHERE p.name = 'Alice' RETURN friend) makes graph queries readable and self-documenting in ways recursive SQL cannot match. - GraphRAG combines vector embeddings for semantic retrieval with graph traversal for structural context, delivering measurably better multi-hop reasoning than either approach alone.
- Store entity relationships in the graph and dense embeddings in your vector store — they are complementary data structures, not alternatives.
- Graph databases win on traversal and explainability; relational databases win on aggregation and ecosystem maturity; the right production stack often uses both alongside a vector store.
Working with JusDB on Database Architecture
Choosing between Neo4j, PostgreSQL, a vector store, or a hybrid of all three is an architectural decision with long-term cost and performance implications. The right answer depends on your query patterns, team expertise, update frequency, and budget — and getting it wrong at the design stage is far more expensive than getting it right. JusDB's database consultants have architected graph, relational, and vector database stacks for production AI applications across healthcare, fintech, and developer tooling. Whether you are evaluating Neo4j for the first time or optimizing a GraphRAG pipeline that is already in production, we can help you make the call with confidence.