- Apache Pinot is a real-time OLAP store optimized for user-facing analytics, not internal BI.
- Kafka-based stream ingestion delivers freshness in seconds with no batch window.
- The StarTree index removes the need for pre-aggregation cubes and accelerates multi-column GROUP BY queries by orders of magnitude.
- Tenant isolation keeps noisy-neighbor latency spikes away from high-priority query paths.
- Properly tuned Pinot clusters can sustain p99 < 50 ms at billion-row scale with dozens of concurrent users.
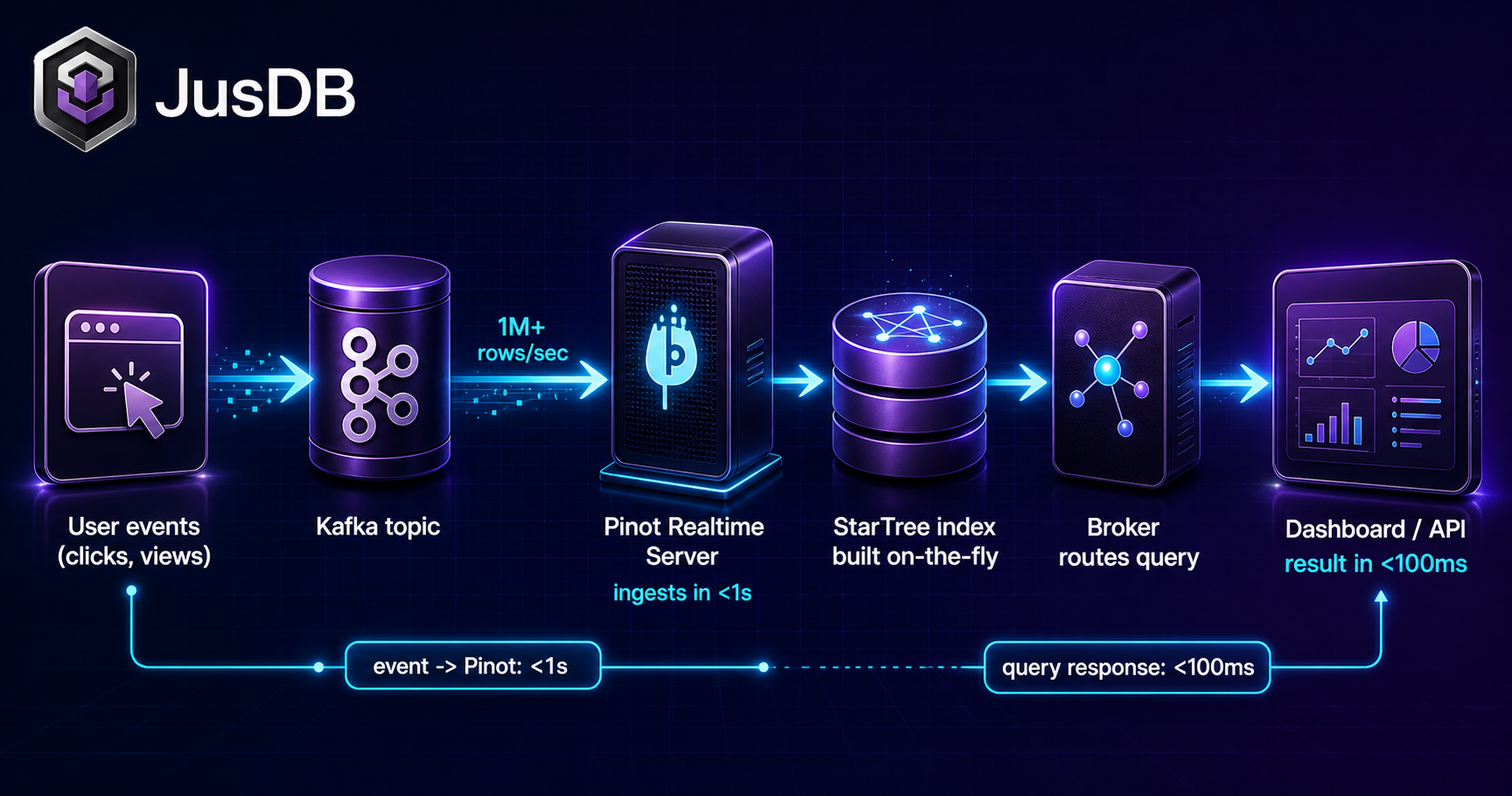
Why Pinot for User-Facing Analytics
Most analytical databases were designed around a single trust boundary: internal analysts who accept seconds of latency. The moment analytics move into the product itself — per-user dashboards, real-time leaderboards, "activity in the last 5 minutes" feeds — that boundary collapses. End users expect the same sub-second response they get from any other API call, and they will abandon a dashboard that feels slow.
Pinot addresses this with a column-store architecture that separates completed (offline) segments from consuming (realtime) segments. Offline segments are deeply indexed and immutable; realtime segments absorb new events from Kafka and are periodically flushed and converted. A single query fan-out layer — the Broker — merges results across both segment types transparently, so callers always see a unified, up-to-date view.
Three architectural decisions make Pinot uniquely suitable for user-facing workloads:
- Inverted and sorted indexes push predicate filtering into segment-local storage, avoiding full-column scans.
- StarTree indexes pre-aggregate common GROUP BY combinations at write time, enabling instant aggregation without full scan rollups.
- Tenant isolation lets you assign dedicated server pools to high-SLA query paths, so a runaway analytical job never degrades the user-facing API.
LinkedIn's original use case — "Who viewed my profile?" — required joining user activity against a graph of hundreds of millions of profiles with p99 under 100 ms. Standard columnar stores could not meet that bar. Pinot could, and the pattern has since been replicated at Uber (driver/rider analytics), Walmart (in-store sensor aggregation), and dozens of other high-traffic platforms.
When evaluating Pinot for your workload, measure query fan-out first. If a typical dashboard query touches more than 30–40 servers in parallel, you should re-examine your partition key and segment count. Over-partitioning increases coordination overhead and can invert the latency benefit.
Real-Time Ingestion from Kafka
Pinot's realtime ingestion path starts with a Low-Level Consumer (LLC) topology where each Pinot server is assigned one or more Kafka partition offsets. Servers write incoming records into an in-memory consuming segment; when the segment crosses a row-count or time threshold it is flushed to deep storage (S3, GCS, HDFS) and indexed. This flush-and-replace cycle keeps memory usage bounded while delivering freshness that is typically under 30 seconds end-to-end from Kafka produce to query visibility.
The table configuration below shows a production-style realtime table definition. Key decisions to call out: segmentsConfig.replicasPerPartition controls fault tolerance, streamConfigs.stream.kafka.consumer.type must be lowlevel for offset-granular commits, and realtime.segment.flush.threshold.rows governs segment size versus freshness trade-off.
{
"tableName": "user_events_REALTIME",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "event_ts_millis",
"timeType": "MILLISECONDS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "30",
"segmentPushType": "APPEND",
"replicasPerPartition": "2"
},
"tenants": {
"broker": "user_facing_broker",
"server": "user_facing_server"
},
"tableIndexConfig": {
"loadMode": "MMAP",
"sortedColumn": ["user_id"],
"bloomFilterColumns": ["user_id", "session_id"],
"rangeIndexColumns": ["event_ts_millis"],
"starTreeIndexConfigs": [
{
"dimensionsSplitOrder": ["event_type", "country_code", "platform"],
"skipStarNodeCreationForDimensions": [],
"functionColumnPairs": [
"COUNT__*",
"SUM__duration_ms",
"MAX__event_ts_millis"
],
"maxLeafRecords": 10000
}
],
"noDictionaryColumns": ["raw_payload"],
"onHeapDictionaryColumns": ["event_type", "country_code", "platform"]
},
"ingestionConfig": {
"streamIngestionConfig": {
"streamConfigMaps": [
{
"realtime.segment.flush.threshold.rows": "500000",
"realtime.segment.flush.threshold.time": "1h",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "user-events",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka-broker-1:9092,kafka-broker-2:9092",
"stream.kafka.consumer.prop.auto.offset.reset": "largest"
}
]
}
},
"routing": {
"instanceSelectorType": "strictReplicaGroup"
},
"query": {
"timeoutMs": 3000
},
"metadata": {}
}The strictReplicaGroup instance selector ensures that a single query always reads from the same replica group, which is critical for consistent results when a consuming segment is mid-flush on one replica but already persisted on another.
StarTree Index and Multi-Column Optimization
A StarTree index is Pinot's answer to the classic pre-aggregation cube problem — but without the combinatorial explosion of materializing every possible dimension combination. At segment write time, Pinot builds a tree where each node represents a GROUP BY prefix. Aggregation queries that match a prefix node are resolved by reading the pre-aggregated node value rather than scanning raw records. For a 500-million-row segment with three dimensions, this can reduce per-query data read from gigabytes to kilobytes.
The configuration shown in the table JSON above defines a StarTree over event_type, country_code, and platform. The dimensionsSplitOrder matters: dimensions listed first have higher cardinality nodes near the root and deliver greater pruning. Place the dimension with the highest query selectivity first.
functionColumnPairs declares which aggregations are pre-computed. Queries that use only these functions against only these dimensions will hit the StarTree path. Any query that introduces a dimension or function not in the index falls back to the raw column scan — still fast, but not StarTree-fast. A practical rule: audit your top-20 dashboard queries, extract the common GROUP BY skeleton, and encode that as your primary StarTree config. You can define multiple StarTree indexes per table if query patterns diverge significantly across feature teams.
Use Pinot's segment debug endpoint (/debug/tables/{tableName}/segments) to inspect the starTreeIndexSizeBytes field after a segment is built. If the StarTree index is larger than 20% of the total segment size, consider raising maxLeafRecords or narrowing the dimension list — you may be trading storage for marginal latency gain.
Schema and Table Configuration
Pinot schemas enforce strict column-level typing with no late-binding. Every column is classified as a dimension (filterable, group-able), metric (aggregatable), or date-time. This classification drives index selection automatically: dimension columns get inverted indexes by default, metric columns skip them.
{
"schemaName": "user_events",
"dimensionFieldSpecs": [
{ "name": "user_id", "dataType": "LONG" },
{ "name": "session_id", "dataType": "STRING" },
{ "name": "event_type", "dataType": "STRING" },
{ "name": "country_code", "dataType": "STRING" },
{ "name": "platform", "dataType": "STRING" },
{ "name": "page_name", "dataType": "STRING" }
],
"metricFieldSpecs": [
{ "name": "duration_ms", "dataType": "LONG" },
{ "name": "byte_count", "dataType": "LONG" },
{ "name": "error_count", "dataType": "INT" }
],
"dateTimeFieldSpecs": [
{
"name": "event_ts_millis",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}A few schema decisions with outsized performance impact: keep high-cardinality string columns like session_id out of the StarTree index; use noDictionaryColumns for columns that are never filtered (raw payloads, debug blobs) to avoid dictionary encoding overhead; and always define a dateTimeFieldSpec that matches your Kafka message timestamp exactly — a mismatch forces Pinot to parse timestamps on every query.
For multi-value dimension columns (e.g., a list of tags per event), Pinot supports MV columns natively. The inverted index for an MV column is built per-value, so WHERE ARRAYCONTAINS(tags, 'checkout') resolves in constant time regardless of list length.
Query Patterns and Performance
Pinot speaks a subset of ANSI SQL with time-range extension functions. The single most important performance practice for user-facing queries is to always bound the time range using the indexed date-time column. Without a time filter, Pinot must scan all segments including cold historical ones, which can spike latency by 10–50x.
-- Event counts by type for the last 24 hours, StarTree-eligible
SELECT
event_type,
country_code,
COUNT(*) AS event_count,
SUM(duration_ms) AS total_duration_ms,
AVG(duration_ms) AS avg_duration_ms
FROM user_events_REALTIME
WHERE
event_ts_millis >= 1757462400000 -- epoch for T-24h
AND event_ts_millis < 1757548800000
GROUP BY event_type, country_code
ORDER BY event_count DESC
LIMIT 50;-- Per-user session summary for the last 7 days (user_id sorted column)
SELECT
user_id,
COUNT(DISTINCT session_id) AS session_count,
SUM(duration_ms) AS total_engagement_ms,
MAX(event_ts_millis) AS last_seen_ms
FROM user_events_REALTIME
WHERE
user_id = 9871234
AND event_ts_millis >= 1756944000000
AND event_ts_millis < 1757548800000
GROUP BY user_id;-- Funnel analysis: ordered events within a session window
SELECT
session_id,
LASTWITHTIME(event_type, event_ts_millis, 'STRING') AS last_event,
COUNT(*) AS step_count,
MIN(event_ts_millis) AS funnel_start_ms,
MAX(event_ts_millis) AS funnel_end_ms
FROM user_events_REALTIME
WHERE
event_type IN ('page_view', 'add_to_cart', 'checkout_start', 'purchase')
AND event_ts_millis >= 1757462400000
AND event_ts_millis < 1757548800000
GROUP BY session_id
HAVING step_count >= 2
ORDER BY funnel_end_ms DESC
LIMIT 1000;The second query benefits from the sortedColumn: user_id setting in the table config — Pinot can binary-search within a segment for the target user_id and skip the inverted index lookup entirely, shaving another 20–40% off p99 for single-user queries.
For latency benchmarking in production, always measure Broker-reported timeUsedMs alongside wall-clock time. The delta reveals network and serialization overhead. If timeUsedMs is low but wall-clock is high, the bottleneck is in your API gateway or connection pool, not Pinot itself.
- Pinot's consuming/offline dual-segment model gives you real-time freshness without sacrificing the deep indexing that powers low-latency queries.
- Always pair a time-range filter with every user-facing query — it is the single highest-leverage latency optimization available.
- The StarTree index eliminates scan-time aggregation for known GROUP BY patterns; design it around your actual dashboard queries, not a hypothetical future workload.
- Tenant isolation via named broker and server pools is non-negotiable for production: it prevents analytical batch jobs from blowing out your user-facing SLA.
- LinkedIn's 100B+ events/day at p99 < 50 ms benchmark is achievable — but only with correct partition sizing,
strictReplicaGrouprouting, and disciplined query time-bounding. - Monitor segment StarTree index size ratios and flush thresholds continuously; both drift as data volumes grow and can silently degrade performance over weeks.
Working with JusDB on Apache Pinot
Deploying Apache Pinot for user-facing analytics involves substantially more production surface area than running a standard data warehouse: Kafka consumer lag monitoring, segment compaction schedules, StarTree rebuild cycles on schema changes, broker routing configuration, and latency SLA alerting all require sustained operational expertise. JusDB's database engineering team has designed and operated Pinot clusters across high-traffic consumer products, and we know exactly where the sharp edges are — from misconfigured maxLeafRecords causing bloated segments to inverted-index cardinality explosions that quietly double memory usage over a weekend.
Whether you are evaluating Pinot as a replacement for a slow dashboard data store, migrating an existing Druid or ClickHouse deployment, or tuning an existing cluster that has started missing latency targets, JusDB can accelerate every phase: schema design, table configuration review, Kafka ingestion topology, StarTree index strategy, and on-call runbook authoring. We work alongside your engineering team rather than replacing it, and every engagement ends with your team fully capable of running the system independently.