TL;DR — InnoDB architecture in 60 seconds: InnoDB is MySQL's transactional storage engine — ACID, row-level locking, MVCC. Its three critical RAM regions: buffer pool (cached data/index pages, size to 60-80% of system RAM via innodb_buffer_pool_size), change buffer (deferred secondary-index updates for non-unique indexes), and log buffer (in-memory redo log, flushed to disk on commit). On disk: .ibd tablespaces hold table data as clustered B+ trees keyed by primary key, redo log provides crash-recovery via WAL, undo log backs MVCC. Production tuning levers in 2026: innodb_buffer_pool_size (most important), innodb_log_file_size (recovery time), innodb_flush_log_at_trx_commit (durability vs throughput), innodb_io_capacity (NVMe-appropriate I/O). MySQL 8.4 LTS adds parallel DDL and HyperGraph optimizer on top — both rely on this same InnoDB foundation.
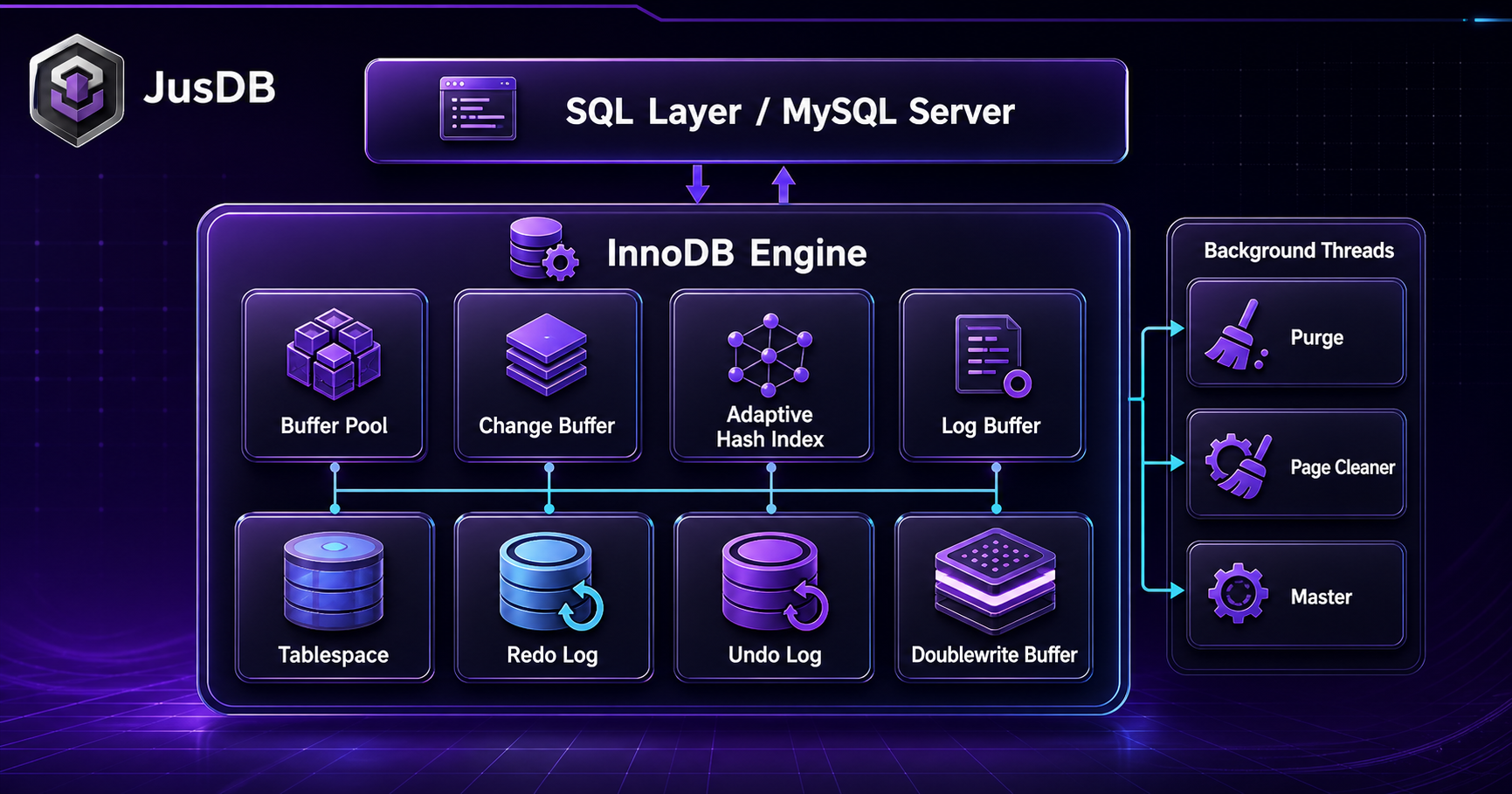
InnoDB is why MySQL survived the NoSQL wave. The storage engine that ships with every MySQL installation handles ACID transactions, row-level locking, crash recovery, and MVCC — all without configuration. Understanding how InnoDB works internally is what separates MySQL performance tuning from guesswork: buffer pool pressure, the redo log bottleneck, change buffer behavior, and lock escalation all have direct explanations in the InnoDB architecture.
This guide maps InnoDB's internals with enough depth to diagnose real production problems.
Introduction to InnoDB
InnoDB is a general-purpose storage engine that balances high reliability and high performance through its sophisticated multi-layered architecture. What sets InnoDB apart from other storage engines is its comprehensive approach to data integrity, featuring full ACID compliance with transaction support, crash recovery capabilities, and multi-version concurrency control (MVCC).
The engine's architecture is fundamentally divided into two main categories: in-memory structures that manage active data and optimize performance, and on-disk structures that ensure data persistence and integrity. This dual-layer approach enables InnoDB to deliver exceptional performance while maintaining the strict consistency guarantees required by enterprise applications.
In-Memory Structures: The Performance Engine
Buffer Pool - The Heart of InnoDB
The buffer pool represents InnoDB's most critical in-memory component, serving as the primary cache for table and index data. Located in main memory, the buffer pool permits frequently used data to be accessed directly from RAM, dramatically reducing disk I/O operations and accelerating query processing.
Architecture and Organization
The buffer pool is organized as a collection of fixed-size pages, typically 16KB each (configurable via innodb_page_size). On dedicated database servers, it's recommended to allocate 60-80% of available physical memory to the buffer pool through the innodb_buffer_pool_size parameter. For example, on a server with 32GB of RAM, allocating 24-26GB to the buffer pool provides optimal performance for most workloads.
The buffer pool implements a sophisticated variation of the Least Recently Used (LRU) algorithm, dividing pages into two sublists: the "new" sublist containing recently accessed pages, and the "old" sublist for less frequently accessed data. This design prevents occasional full table scans from flushing out frequently used data, maintaining cache efficiency even under variable workload conditions.
Advanced Buffer Pool Features
Modern MySQL implementations support multiple buffer pool instances to reduce contention in high-concurrency environments. The innodb_buffer_pool_instances variable controls this partitioning, with each instance managing its own free lists, flush lists, and LRU structures independently. Each buffer pool instance should ideally be at least 1GB for optimal efficiency.
The buffer pool also supports dynamic resizing since MySQL 5.7, allowing administrators to adjust memory allocation without restarting the server. This operation occurs in chunks defined by innodb_buffer_pool_chunk_size (default 128MB), providing flexibility for changing workload demands.
Buffer Pool Monitoring and Optimization
Key performance indicators for buffer pool effectiveness include:
- Buffer pool hit ratio: Should exceed 99% for optimal performance
- Pages read vs. read requests: Low ratio indicates good cache efficiency
- Free buffer availability: Monitored via innodb_buffer_pool_wait_free status
Change Buffer - Optimizing Secondary Index Operations
The change buffer represents one of InnoDB's most innovative performance optimizations, specifically designed to accelerate secondary index maintenance. This specialized data structure caches changes to secondary index pages when those pages are not currently in the buffer pool, significantly reducing random I/O operations.
How Change Buffer Works
When INSERT, UPDATE, or DELETE operations modify secondary indexes, InnoDB faces a challenge: secondary indexes are typically non-unique and updates occur in relatively random order. Without the change buffer, each modification would require reading the corresponding index page from disk, updating it, and writing it back - a process that generates substantial random I/O.
The change buffer elegantly solves this problem by temporarily storing index changes in memory when the target pages aren't cached. These buffered changes are later merged when the affected pages are naturally loaded into the buffer pool by other operations, converting multiple random I/O operations into efficient sequential processing.
Change Buffer Configuration
The behavior of the change buffer is controlled by several key parameters:
- innodb_change_buffering: Controls which operations are buffered (all, none, inserts, deletes, changes, purges)
- innodb_change_buffer_max_size: Defines maximum change buffer size as percentage of buffer pool
- The change buffer is part of the system tablespace on disk, ensuring persistence across restarts
Limitations and Considerations
The change buffer provides significant benefits for workloads with many secondary indexes and random insertion patterns, but it's not universally applicable. It doesn't support indexes with descending columns or when the primary key contains descending columns. Additionally, change buffer merging can take considerable time during recovery scenarios with many pending changes.
Adaptive Hash Index - Accelerating B-Tree Performance
The adaptive hash index (AHI) represents InnoDB's intelligent approach to further accelerating already-fast B-tree lookups. This in-memory hash index is automatically constructed based on observed query patterns, potentially providing O(1) lookup performance for frequently accessed data.
Adaptive Hash Index Operation
InnoDB continuously monitors index usage patterns, and when it detects that certain index values are repeatedly accessed, it creates hash index entries pointing directly to the corresponding buffer pool pages. The hash keys can be either full index values or prefixes, depending on usage patterns.
This optimization is particularly effective for workloads with highly repetitive key lookups. However, the AHI requires careful consideration of its overhead - maintaining the hash structure consumes memory and CPU cycles, which may not be justified for all workload patterns.
Configuration and Tuning
The adaptive hash index is controlled by the innodb_adaptive_hash_index variable, with different defaults across MySQL versions (enabled in MySQL 5.7, disabled by default in MySQL 8.4). The feature can be dynamically enabled or disabled based on workload characteristics.
For high-concurrency environments, the innodb_adaptive_hash_index_parts variable (default 8, maximum 512) partitions the hash index to reduce contention. Performance monitoring should include checking for btr0sea.c latch waits, which indicate potential AHI contention.
Log Buffer - Staging Redo Log Entries
The log buffer serves as the staging area for redo log records before they're written to disk. This in-memory structure allows InnoDB to batch redo log writes efficiently, converting many small write operations into larger, more efficient disk operations.
Log Buffer Management
The log buffer size is controlled by innodb_log_buffer_size (default typically 16MB). For most applications, the default size is sufficient, but write-intensive workloads may benefit from larger log buffers. The buffer operates on a circular basis, with background threads periodically flushing contents to disk.
The frequency of log buffer flushing is governed by innodb_flush_log_at_trx_commit, which offers three modes:
- 0: Log buffer flushed to disk approximately once per second
- 1: Log buffer flushed at each transaction commit (maximum durability)
- 2: Log buffer written to OS cache at commit, flushed to disk approximately once per second
On-Disk Structures: Ensuring Durability and Integrity
Tablespaces - The Foundation of Data Storage
InnoDB organizes all data within tablespaces - logical storage containers that map to physical files on disk. The tablespace architecture has evolved significantly, moving from a single system tablespace model to a more flexible file-per-table approach.
System Tablespace
The system tablespace (typically ibdata1) serves as the central repository for critical metadata including:
- Data dictionary information
- Undo logs (in older versions)
- Change buffer storage
- Default location for user tables (if file-per-table is disabled)
The system tablespace is configured via innodb_data_file_path and can consist of multiple files with automatic extension capabilities.
File-Per-Table Tablespaces
Modern InnoDB implementations default to file-per-table tablespaces, where each table and its associated indexes are stored in separate .ibd files. This approach provides several advantages:
- Simplified backup and restore operations
- Better space management and reclamation
- Improved portability of individual tables
- Easier monitoring of per-table storage utilization
General and Undo Tablespaces
General tablespaces, created via CREATE TABLESPACE, allow multiple tables to share storage space, providing memory efficiency benefits when many tables share similar characteristics. Undo tablespaces store undo logs separately from the system tablespace, improving manageability and allowing for truncation operations.
Redo Log - Ensuring Durability
The redo log system forms the cornerstone of InnoDB's crash recovery capabilities, implementing write-ahead logging (WAL) to ensure that no committed transaction is ever lost, even in the event of unexpected system failure.
Redo Log Architecture
InnoDB maintains redo logs as a circular buffer of files, typically named with the pattern #ib_redoN. The system attempts to maintain approximately 32 redo log files, each sized to accommodate 1/32 of the total redo log capacity defined by innodb_redo_log_capacity.
The redo log captures all modifications at a very granular level, recording changes in terms of affected records rather than entire pages. Each redo log entry is tagged with a Log Sequence Number (LSN) - a globally unique, ever-increasing identifier that enables precise tracking of database state.
Redo Log Management
The redo log operates on several key principles:
- Circular Operation: As old log files become unnecessary (their changes have been checkpointed), they're reused for new entries
- Fuzzy Checkpointing: InnoDB periodically flushes dirty pages from the buffer pool, advancing the checkpoint LSN
- Recovery Guarantee: The redo log ensures all committed changes can be replayed, even if they weren't written to data files before a crash
Key configuration parameters include:
- innodb_redo_log_capacity: Total disk space for redo logs (adjustable at runtime in MySQL 8.0.30+)
- innodb_log_group_home_dir: Directory location for redo log files
LSN and Checkpointing
The LSN system provides several critical reference points:
- Current LSN: Latest position in redo log
- Flushed LSN: Last position synchronized to disk
- Checkpoint LSN: Point up to which all changes are guaranteed written to data files
The difference between current LSN and checkpoint LSN represents the "checkpoint age" - the amount of recovery work required if a crash occurs.
Undo Logs - Supporting Transactions and MVCC
Undo logs serve dual purposes in InnoDB's architecture: enabling transaction rollback operations and supporting Multi-Version Concurrency Control (MVCC) for consistent reads. These logs maintain previous versions of modified data, allowing multiple transactions to access consistent snapshots without blocking each other.
Undo Log Structure
Undo logs are organized into tablespaces (typically innodb_undo_001 and innodb_undo_002 by default) and contain records of the previous state of data before modifications. Each undo record includes sufficient information to reverse a specific change, whether it's an INSERT, UPDATE, or DELETE operation.
The undo logs operate as a history list, maintaining chains of record versions that enable MVCC. When a transaction needs to read data that has been modified by other transactions, it can traverse these chains to find the appropriate version based on its read view.
Purge Operations
The purge system, controlled by background purge threads, is responsible for cleaning up undo logs that are no longer needed. The number of purge threads is controlled by innodb_purge_threads (default varies by MySQL version and system specifications), with the purge system automatically distributing work among available threads.
Purge operations become critical in high-throughput environments where undo logs can accumulate rapidly. The "History list length" shown in SHOW ENGINE INNODB STATUS indicates the amount of unpurged undo work - high values may indicate insufficient purge capacity or long-running transactions preventing cleanup.
Doublewrite Buffer - Guardian Against Partial Writes
The doublewrite buffer provides a crucial safety mechanism protecting against partial page writes - a scenario where a system crash occurs during the writing of a database page, leaving the page in a corrupted state that cannot be repaired using redo logs alone.
Doublewrite Buffer Operation
When InnoDB flushes dirty pages from the buffer pool, it follows a two-step process:
- Write to Doublewrite Buffer: Pages are first written to a special doublewrite area
- Write to Final Location: After confirming the doublewrite buffer write, pages are written to their final tablespace locations
This approach ensures that if a partial write occurs during step 2, InnoDB can recover the complete page from the doublewrite buffer during crash recovery.
Configuration and Performance
The doublewrite buffer is controlled by innodb_doublewrite with several options:
- ON/DETECT_AND_RECOVER: Full doublewrite protection (default)
- DETECT_ONLY: Writes metadata but not page content to doublewrite buffer
- OFF: Disables doublewrite buffer (not recommended for production)
Modern InnoDB implementations create separate doublewrite files rather than storing doublewrite data in the system tablespace. The number and location of these files can be controlled via innodb_doublewrite_files and innodb_doublewrite_dir.
For storage systems that provide atomic write guarantees (like certain NVMe devices), the doublewrite buffer may be automatically disabled, as the hardware-level atomicity eliminates the risk of partial writes.
Background Threads: The Silent Workers
InnoDB relies on several categories of background threads to manage its complex operations efficiently. These threads handle everything from I/O operations to maintenance tasks, ensuring optimal performance and system health.
Master Thread - The Coordinator
The master thread serves as InnoDB's central coordinator, orchestrating various maintenance activities and ensuring system health. Its responsibilities include:
- Coordinating overall InnoDB activity
- Managing maintenance operations during idle periods
- Orchestrating shutdown procedures
- Monitoring system health and triggering adaptive responses
I/O Threads - Managing Disk Operations
InnoDB uses separate threads for read and write operations to maximize I/O efficiency:
- Read I/O Threads: Handle asynchronous read operations from disk
- Write I/O Threads: Manage asynchronous write operations to disk
The number of I/O threads is controlled by innodb_read_io_threads and innodb_write_io_threads (typically 4 each by default). For most workloads, the default values are sufficient, but high-I/O environments may benefit from tuning these parameters based on storage capabilities.
Page Cleaner Threads - Flushing Dirty Pages
Page cleaner threads are responsible for flushing dirty pages from the buffer pool to disk, a critical operation for maintaining system performance and ensuring crash recovery capabilities. Prior to MySQL 5.6, this function was handled by the master thread, but dedicated page cleaner threads provide better performance and responsiveness.
The number of page cleaner threads is controlled by innodb_page_cleaners (default 4 in recent versions), with each thread capable of working on different buffer pool instances. The page cleaners implement sophisticated algorithms to determine when and how aggressively to flush pages based on:
- Percentage of dirty pages in buffer pool
- Redo log space utilization
- I/O capacity and current load
Key configuration parameters include:
- innodb_max_dirty_pages_pct: Maximum percentage of dirty pages before aggressive flushing (default 90%)
- innodb_max_dirty_pages_pct_lwm: Low watermark for initiating flushing (default 10%)
- innodb_lru_scan_depth: How deep into LRU list to scan for dirty pages per buffer pool instance
Purge Threads - Cleaning Up After Transactions
Purge threads handle the cleanup of undo logs and deleted record versions, playing a crucial role in maintaining system performance and storage efficiency. The number of purge threads is controlled by innodb_purge_threads with defaults varying based on system specifications.
Purge operations include:
- Removing old undo log entries that are no longer needed for MVCC
- Cleaning up deleted record versions
- Truncating undo tablespaces when possible
- Managing the history list of committed transactions
The purge system operates on a batch processing model, with innodb_purge_batch_size controlling how many undo pages are processed in each batch (default 300). In multi-threaded purge configurations, this batch size is divided among available purge threads.
Performance Optimization and Monitoring
Key Performance Indicators
Monitoring InnoDB's architecture requires attention to several critical metrics:
Buffer Pool Metrics:
- Buffer pool hit ratio (target >99%)
- Free buffer availability
- Pages read vs. read requests ratio
I/O Metrics:
- Read and write operations per second
- Average I/O wait times
- Pending I/O operations
Transaction Metrics:
- History list length (should remain low)
- Lock wait statistics
- Deadlock frequency
Log System Metrics:
- LSN progression rate
- Checkpoint age
- Log write frequency and volume
Configuration Best Practices
Memory Allocation:
- Allocate 60-80% of available RAM to innodb_buffer_pool_size on dedicated database servers
- Configure multiple buffer pool instances for servers with >8GB buffer pools
- Size log buffer appropriately for write workload (innodb_log_buffer_size)
Concurrency Settings:
- Match innodb_page_cleaners to innodb_buffer_pool_instances for optimal flushing
- Configure purge threads based on transaction volume
- Tune I/O thread counts based on storage subsystem capabilities
Durability vs Performance Trade-offs:
- Set innodb_flush_log_at_trx_commit=1 for maximum durability
- Consider =2 for better performance with minimal durability risk
- Size redo log capacity to minimize checkpoint frequency while ensuring reasonable recovery times
Advanced Topics and Future Considerations
MVCC and Transaction Isolation
InnoDB's Multi-Version Concurrency Control implementation enables high concurrency while maintaining ACID properties. The system maintains multiple versions of data rows, allowing different transactions to see consistent snapshots based on their isolation level and start time.
The four isolation levels supported (READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE) each provide different guarantees about data consistency and concurrency, with REPEATABLE READ as the default providing an excellent balance for most applications.
Adaptive Algorithms
Modern InnoDB implementations include numerous adaptive algorithms that automatically tune system behavior based on observed workload patterns:
- Adaptive flushing adjusts dirty page flushing rates based on redo log utilization
- Adaptive hash index creation based on access patterns
- Adaptive purge thread utilization based on system load
- Dynamic I/O capacity adjustment based on system capabilities
Modern Storage Considerations
InnoDB's architecture continues evolving to take advantage of modern storage technologies:
- NVMe and SSD optimizations reduce the benefits of certain traditional optimizations like neighbor page flushing
- Atomic write capabilities on modern storage can eliminate the need for doublewrite buffering
- Increased memory capacities allow for larger buffer pools and different caching strategies
Conclusion
InnoDB's sophisticated architecture represents decades of database engineering refinement, providing a robust foundation for demanding applications. Its multi-layered approach, combining efficient in-memory structures with durable on-disk storage, delivers exceptional performance while maintaining strict consistency guarantees.
Understanding InnoDB's architecture enables database administrators and developers to make informed decisions about configuration tuning, capacity planning, and application design. As workloads and hardware continue to evolve, InnoDB's adaptive algorithms and configurable parameters provide the flexibility needed to optimize performance for diverse requirements.
The key to successful InnoDB deployment lies in understanding the interplay between its various components - from the buffer pool's caching strategies to the redo log's durability guarantees. By monitoring key performance indicators and tuning parameters based on actual workload characteristics, organizations can unlock the full potential of this powerful storage engine.
Whether deploying a small application or managing enterprise-scale databases, InnoDB's proven architecture provides the reliability, performance, and scalability needed for modern data-intensive applications. Its continued evolution ensures that it remains at the forefront of database technology, adapting to new hardware capabilities while maintaining its core principles of data integrity and performance excellence.
This comprehensive guide represents current best practices and architectural understanding as of MySQL 8.4. For the latest updates and detailed configuration guidance, consult the official MySQL documentation and consider professional database administration training for complex deployments.
Further Reading
For more in-depth information, check out these authoritative resources:
Related Articles
Explore more database insights from JusDB:
Working with JusDB on MySQL Internals
InnoDB tuning goes deeper than setting innodb_buffer_pool_size. Redo log sizing, change buffer configuration, lock timeout tuning, and identifying which specific InnoDB component is your bottleneck all require reading the right metrics. We tune InnoDB as part of our MySQL consulting work. If you're hitting InnoDB performance limits, reach out.
Related reading: MySQL Performance Tuning | MySQL Architecture Deep Dive | MySQL Timeout Variables
InnoDB in 2026: What Changed Since This Guide Was First Written
InnoDB's core architecture (clustered B+ trees, MVCC, WAL via redo log) has been stable since MySQL 5.6. But the operational best-practices have shifted significantly between MySQL 5.7, 8.0, and 8.4 LTS — and the tuning advice from 2022 is wrong on several counts in 2026.
innodb_buffer_pool_size — Modern Targets and Auto-Tuning
The old rule "70-80% of RAM" still holds, but MySQL 8.0+ introduced buffer pool resizing without restart via SET GLOBAL innodb_buffer_pool_size = 64G. The resize happens in-place by allocating/freeing buffer pool instances; allow 10-30 seconds for the operation to complete. innodb_buffer_pool_instances defaults to 8 in 8.0+ (was 1 in 5.6) — leave it alone unless your buffer pool exceeds 64GB, in which case set it to buffer_pool_size / 8GB. Monitoring: Innodb_buffer_pool_pages_data / Innodb_buffer_pool_pages_total should be near 1.0 for cache-resident workloads; if it drops below 0.95 sustained, the buffer pool is too small for the active dataset.
Redo Log Sizing — Major Changes in 8.0+
Pre-8.0, you had to set both innodb_log_file_size and innodb_log_files_in_group explicitly. In 8.0+, the redo log is dynamic: 32 files of 1GB each by default, automatically managed. Configure size via innodb_redo_log_capacity (default 100MB total — way too small for production). Production rule: set to 1-2× your sustained write throughput per minute. For a workload generating 500MB/min of redo data, set innodb_redo_log_capacity = 4G. Too small = checkpoint flushing thrash; too large = longer crash recovery but smoother runtime.
innodb_flush_log_at_trx_commit — Durability vs Throughput
This is the single most impactful durability knob. =1 (default, full durability) — flush log + fsync on every commit; safest, slowest. =2 — write to OS but don't fsync; lose ≤1 second on OS crash, instance crash safe. =0 — write/fsync only every second; can lose 1 second of commits on instance crash. For OLTP with strict durability: =1. For high-throughput logging / analytics ingest where some tail loss is acceptable: =2. Never =0 in production.
The Doublewrite Buffer in 8.0+ — Now Configurable
The doublewrite buffer protects against torn-page writes (partial-block writes during power loss). In MySQL 8.0.20+, it became configurable via separate doublewrite buffer files (#ib_16384_*.dblwr) rather than a section of the system tablespace — fewer write contention pathologies on high-throughput systems. Modern NVMe storage often makes the doublewrite buffer redundant (atomic writes), but disable only if you've verified your storage's atomic-write guarantees: innodb_doublewrite=OFF can deliver 10-15% write throughput gains.
Parallel Operations in 8.0+ and 8.4
Modern InnoDB scales reads and DDL across many threads. innodb_parallel_read_threads (default 4) parallelizes CHECK TABLE, parallel SELECT scans, and parallel index builds. innodb_ddl_threads (8.0.27+, default 4) parallelizes ALTER TABLE ADD INDEX. On modern 16-64 core hardware, both should be increased — see our MySQL 8.4 Parallel DDL guide for benchmark-backed settings.
Production Tuning Checklist for 2026
For a new production InnoDB deployment on 16-64 core / 128-512GB RAM / NVMe storage: innodb_buffer_pool_size = 70% of RAM, innodb_buffer_pool_instances = buffer_pool_size_GB / 8, innodb_redo_log_capacity = 4-8G, innodb_flush_log_at_trx_commit = 1, innodb_io_capacity = 2000 (NVMe), innodb_io_capacity_max = 4000, innodb_parallel_read_threads = 16, innodb_ddl_threads = 8, innodb_flush_method = O_DIRECT (Linux). These defaults cover 90% of OLTP workloads; tune from monitoring data, not from blog rules of thumb.
Frequently Asked Questions
What is the most important InnoDB tuning parameter?
innodb_buffer_pool_size by a large margin. It's the in-memory cache of data and index pages — reads from the buffer pool are 100,000× faster than reads from disk. Set it to 60-80% of system RAM on a dedicated MySQL host. Default is 128MB, which is absurdly small for any production system — leaving the default is the #1 reason for sluggish MySQL deployments.How does InnoDB's MVCC work?
innodb_undo_log_truncate) and tombstone bloat that VACUUM-like purge threads clean up in the background.What is the InnoDB doublewrite buffer?
innodb_doublewrite=OFF).Should I use innodb_flush_log_at_trx_commit=1, 2, or 0?
How do I size the InnoDB redo log?
innodb_redo_log_capacity (combined size of all redo log files, default 100MB). Rule: 1-2× your sustained write throughput per minute. For a workload generating 500MB/min of redo, set 4GB. Too small causes checkpoint flushing thrash (visible as I/O spikes and Innodb_log_waits in SHOW STATUS). Too large extends crash recovery time. Monitor Innodb_log_waits — it should be near zero in production.What does innodb_io_capacity actually do?
innodb_io_capacity_max to 2× this. Too low = bufferp pool fills with dirty pages and stalls. Too high = excess background I/O competes with OLTP queries. Most production deployments leave the default 200, which is wrong for any modern hardware.Why is my InnoDB buffer pool hit ratio low?
innodb_buffer_pool_size. (2) Massive table scans evict hot pages — investigate slow queries with EXPLAIN and add indexes. (3) Recent server restart or buffer pool resize — hit ratio rebuilds over minutes-to-hours as queries warm the cache. MySQL 5.7+ supports innodb_buffer_pool_dump_at_shutdown and innodb_buffer_pool_load_at_startup to persist hot pages across restarts.What are common InnoDB production mistakes?
innodb_buffer_pool_size at 128MB. (2) Not increasing innodb_redo_log_capacity from 100MB. (3) Setting innodb_flush_log_at_trx_commit=0 in production. (4) Ignoring Innodb_row_lock_waits — a sign of contention requiring index or query changes. (5) Running auto-extend system tablespace until disk fills. (6) Not enabling innodb_file_per_table (it's default since 5.6 but legacy migrations sometimes lose it).