TL;DR — MySQL Group Replication in 60 seconds: Group Replication is MySQL's native synchronous (well, almost — eventually consistent with certification) replication based on Paxos. Each transaction is broadcast to all group members for certification before commit; any conflict with concurrent transactions on other nodes causes rollback. Two modes: single-primary (default — one writer, automatic failover; equivalent to async replication with HA) and multi-primary (all members writable; useful for geo-distributed writes but conflict-heavy workloads cripple it). Production reality in 2026: most teams deploy single-primary Group Replication via InnoDB Cluster (MySQL Shell + MySQL Router as the management layer) for HA. Multi-primary is rarely used; the alternative for active-active is Percona XtraDB Cluster or MariaDB Galera — both also Paxos-based but with different tradeoffs. Group Replication requires GTID, row-based binlog, and InnoDB.
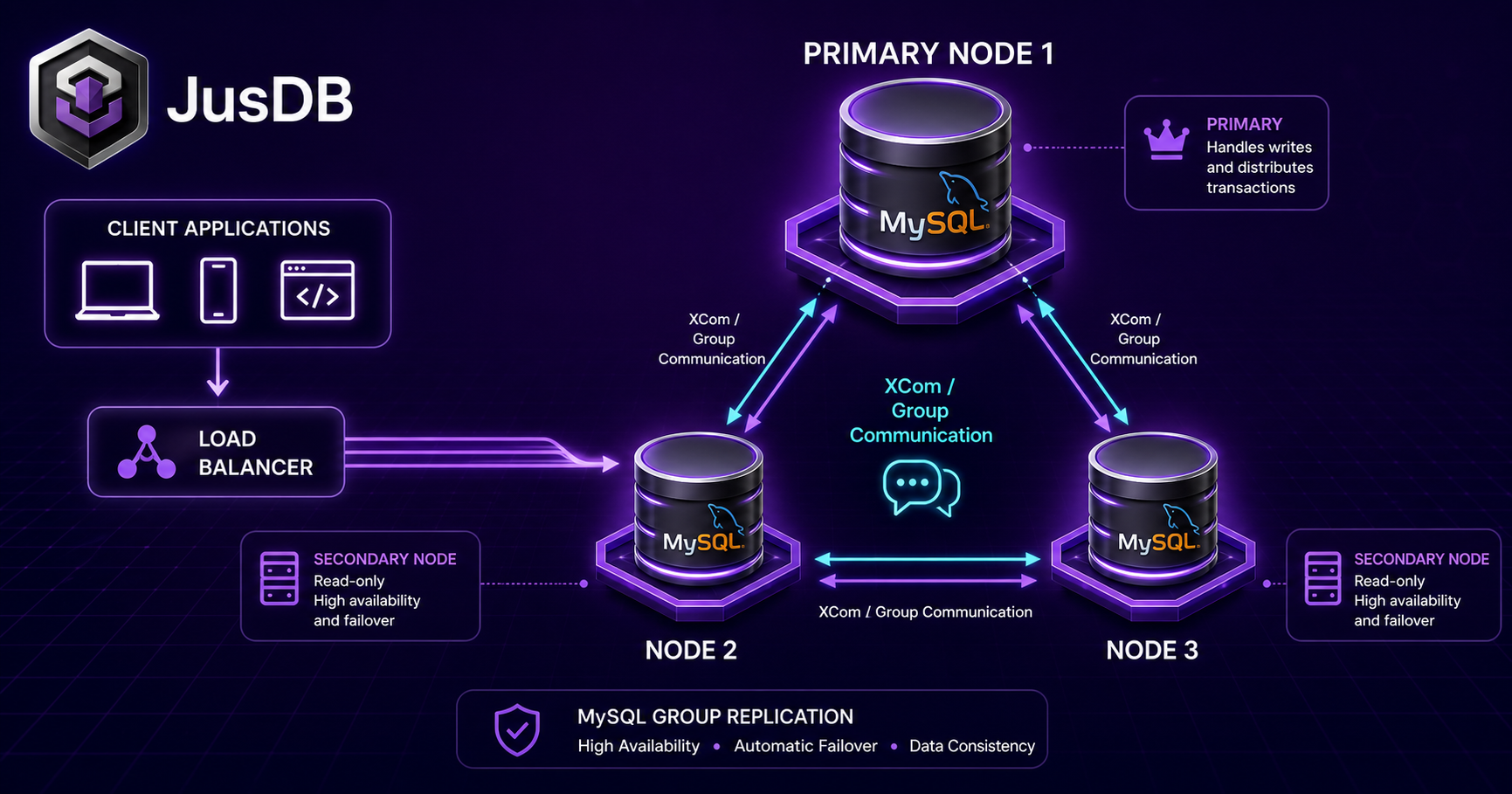
MySQL Group Replication is the consensus layer that powers InnoDB Cluster — and the reason you can have automatic failover without data loss. When the primary crashes, the two surviving nodes have already committed every transaction the primary acknowledged, because Group Replication's Paxos protocol requires a quorum to commit. No ETL, no data loss, sub-30-second failover. This guide covers the configuration that makes it work reliably in production.
1 — Concepts
Group Replication is designed to create a self-healing cluster of MySQL servers. Each server maintains a full copy of the data and participates in a consensus protocol to validate transactions before committing them. This ensures strong consistency and automated failover.
- Available as a built-in plugin since MySQL 5.7.17.
- No third-party software required—native to MySQL.
- Implements Paxos consensus for membership negotiation, failure detection, and message delivery.
- Supports SINGLE-PRIMARY mode (simpler, one writer) and MULTI-PRIMARY mode (all writable, conflict resolution required).
- Requires at least 3 servers (recommended maximum: 9).
- Automatic split-brain protection ensures safe behavior under network partitions.
2 — Deployment Modes
2.1 Single-Primary Mode
The default mode where a single node acts as the primary (writer) and others serve as secondaries (read replicas). If the primary fails, the cluster automatically elects a new primary. This is the recommended mode for most workloads JusDB manages for our clients.
2.2 Multi-Primary Mode
All nodes accept writes, and conflicts are resolved using a “first committer wins” rule. Nodes joining the cluster first recover data before becoming fully online. While more flexible, this mode introduces complexity and limitations.
3 — Basic Requirements
- Only the InnoDB storage engine is supported.
- All tables must have primary keys.
- GTID mode must be enabled.
- Binary log format must be set to ROW.
4 — Benefits
Group Replication automates what previously required manual intervention, including:
- Automatic failover: When a node fails, the group elects a new primary seamlessly.
- Fault tolerance: Built-in quorum and consistency safeguards.
- Operational simplicity: Less reliance on external tooling.
- Scalability: Distribute read workloads across multiple replicas.
5 — Configuring Group Replication
5.1 OS-Level Preparation
- Enable passwordless SSH for the
mysqluser. - Open firewall ports
3306and33061between all members. - Configure or disable SELinux appropriately.
5.2 Create Replication User
CREATE USER 'usr_replication'@'10.0.1.%' IDENTIFIED BY 'Pass!12345' REQUIRE SSL;
GRANT REPLICATION SLAVE ON *.* TO 'usr_replication'@'10.0.1.%';
FLUSH PRIVILEGES;5.3 Update MySQL Configuration
Key parameters in my.cnf include:
report_hostfor node identity.group_replication_local_addressandgroup_seedsfor member communication.transaction_write_set_extraction=XXHASH64for conflict detection.gtid_mode=ONandenforce_gtid_consistency=ON.
Example for a 3-node cluster:
[mysqld]
server_id=1
bind_address=10.0.1.11
report_host=10.0.1.11
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
group_replication_local_address="10.0.1.11:33061"
group_replication_group_name="ac419792-b575-4f86-b962-e7e0d433f491"
group_replication_group_seeds="10.0.1.11:33061,10.0.1.12:33061,10.0.1.13:33061"5.4 Configure Replication Channel
CHANGE REPLICATION SOURCE TO
SOURCE_USER='usr_replication',
SOURCE_PASSWORD='Pass!12345'
FOR CHANNEL 'group_replication_recovery';5.5 Install Plugin
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
SHOW PLUGINS;5.6 Bootstrap the Primary Node
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;5.7 Add Remaining Nodes
START GROUP_REPLICATION;
SELECT * FROM performance_schema.replication_group_members;If you encounter duplicate UUID errors, remove auto.cnf and restart the node.
6 — Handling Failures
- Replica crash: Restart MySQL and run
START GROUP_REPLICATION. - Primary crash: Cluster elects a new primary; restart the failed node and rejoin as replica.
- All nodes down: Requires manual bootstrap again.
7 — ProxySQL Integration
To deliver true application transparency, Group Replication should be combined with ProxySQL. Since version 1.4.0 (and MySQL 8 support from 2.6.0), ProxySQL has native Group Replication support.
7.1 Why Use ProxySQL with Group Replication?
- Seamless failover across primaries and replicas.
- Replica shunning when lag thresholds are exceeded.
- Load balancing between readers and writers.
- Support for multiple clusters.
7.2 Configuration Highlights
- Create a monitoring user on MySQL backends.
- Configure
mysql_group_replication_hostgroupsin ProxySQL to define writer/reader groups. - Enable replica auto-discovery for dynamic scaling.
7.3 Monitoring via ProxySQL
SELECT * FROM monitor.mysql_server_group_replication_log ORDER BY time_start_us LIMIT 20;
SELECT * FROM runtime_mysql_servers;ProxySQL automatically detects failovers and redirects client traffic transparently, ensuring zero downtime for applications.
8 — JusDB Best Practices
- Always deploy an odd number of nodes to maintain quorum.
- Encrypt replication links using SSL for security.
- Use row-based logging to avoid inconsistencies.
- Schedule backups from replicas to reduce load on the primary.
- Purge old binary logs regularly to save space.
- Continuously monitor replication lag, quorum status, and failover metrics.
- Perform failover drills to validate readiness.
9 — Conclusion
MySQL Group Replication is one of the most significant advancements in MySQL’s HA story. It eliminates manual failover, ensures strong consistency, and integrates seamlessly with ProxySQL for production-ready deployments. At JusDB, we design and implement Group Replication clusters that empower businesses to run mission-critical workloads with confidence, scalability, and resilience.
Looking to build a fault-tolerant MySQL environment? Talk to JusDB experts today.
Further Reading
For more in-depth information, check out these authoritative resources:
- MySQL Official Documentation
Working with JusDB on MySQL HA
Group Replication is production-ready when configured correctly — but flow control tuning, quorum management, and the transition to InnoDB Cluster all have real operational complexity. We deploy and operate Group Replication clusters as part of our MySQL consulting work. Reach out.
Related reading: MySQL Group Replication Deep Dive | MySQL InnoDB Cluster Guide | MySQL Performance Tuning
Group Replication Architecture: Certification, Quorum, and Failover
Understanding how Group Replication actually works under the hood is critical for operating it. Most production failures stem from operators treating it like async replication (it isn't) or like synchronous replication (also not exactly).
The Certification Process
When a transaction commits on any node, the writeset (rows touched, with their before/after states) is broadcast to all group members via Paxos. Each member runs certification: did any other concurrent transaction (already certified) modify the same rows? If yes, the new transaction is aborted with error 3101 / 5.6 / 1180. If no, it's queued for application. This is what makes Group Replication "synchronous" in spirit — all members see the same ordered sequence of certified transactions — but "eventually consistent" in practice: members may have applied different prefixes of that sequence at any given moment.
Quorum and Network Partitions
Group Replication uses a majority quorum: a transaction can commit only if a majority of group members are reachable. For a 3-node group, you need 2 members up. For 5, you need 3. Network partitions are the common failure mode: if a minority of nodes becomes isolated, they stop accepting writes (correct behavior — preventing split-brain). The majority partition continues. The isolated nodes must be manually rejoined after the partition heals. Group_replication_unreachable_majority_timeout (default 0, no timeout) controls whether isolated nodes wait forever or eventually self-exit. Production setting: 30-300 seconds.
Single-Primary vs Multi-Primary Mode
Single-primary (default since 8.0): one designated primary handles all writes; secondaries are read-only; automatic failover via election on primary failure. This is what 95% of production deployments use — it gives you HA without the multi-primary complexity. Multi-primary: every member accepts writes; certification handles conflicts; useful for geo-distributed read-write workloads, but write-conflict-heavy workloads (e.g., counters on the same row) become impractical due to certification rollbacks. The MySQL team recommends single-primary for almost all use cases.
InnoDB Cluster — The Recommended Production Pattern
InnoDB Cluster wraps Group Replication with operational tooling: MySQL Shell's dba.createCluster() provisions a group; MySQL Router handles connection routing (writes to primary, reads to secondaries) without app-level awareness. The combination provides true HA — primary fails → election in 5-30 seconds → Router transparently redirects writes to the new primary → app sees only a brief connection error. For new MySQL HA deployments in 2026, InnoDB Cluster is the default; Orchestrator + manual replication is the legacy alternative.
Configuration Requirements
Group Replication has strict prerequisites: binlog_format = ROW, binlog_checksum = NONE (pre-8.0.21), gtid_mode = ON, enforce_gtid_consistency = ON, transaction_write_set_extraction = XXHASH64, all tables must use InnoDB, all tables must have primary keys, and the group's network must support multicast or use the unicast (gcs_xcom) communication stack with explicit member lists. Skipping any of these results in setup-time errors — verify with the MySQL Shell's dba.configureLocalInstance() validator before bringing a node into the cluster.
Operational Gotchas in 2026
(1) Large transactions cause flow control: when one node's apply queue grows, Group Replication throttles all writers across the group. Set group_replication_transaction_size_limit (default 150MB) lower for OLTP. (2) DDL is not "synchronous" in the same sense — DDL statements use online DDL infrastructure, which means schema changes can race against writes during the operation. Always test DDL on a staging cluster. (3) Recovery state is fragile — a node that falls more than group_replication_recovery_complete_at behind cannot rejoin; you must clone (MySQL 8.0+ supports CLONE plugin for fast recovery). (4) Geo-distributed groups work but latency dominates: a 100ms RTT between members caps your per-row write throughput at ~10 commits/sec for that row. Plan accordingly.
Frequently Asked Questions
What is MySQL Group Replication and how is it different from regular replication?
Should I use single-primary or multi-primary mode?
How many nodes should I have in a Group Replication cluster?
Group Replication vs Percona XtraDB Cluster / Galera — which to choose?
How does failover work in MySQL Group Replication?
group_replication_member_weight and member IDs as tiebreakers). The new primary is promoted in 5-30 seconds. MySQL Router (if used) updates its routing table from the cluster metadata and redirects writes transparently. Applications see only a brief connection error during the failover window. Configure connection retry logic in your driver (MySQL Connector/J auto-retries by default in 8.0+).What is the InnoDB Cluster vs Group Replication relationship?
dba.* commands for provisioning, MySQL Router for connection routing, and the cluster metadata schema for orchestration. You can run Group Replication without InnoDB Cluster (managing topology manually), but in 2026 there's no reason to — InnoDB Cluster is the recommended pattern.What happens during a network partition?
group_replication_unreachable_majority_timeout (30-300s) to control whether isolated nodes self-eject after a long partition.What are common Group Replication production issues?
group_replication_flow_control_* variables. (2) Stuck secondary apply — apply lag from contention or slow disks; monitor Replica_running. (3) Failed recovery after long absence — use the CLONE plugin for fast resync. (4) Network partition isolating a node permanently — set group_replication_unreachable_majority_timeout. (5) Schema drift from DDL during partition — use Group Replication's strict-mode validators.